
En Unagi trabajamos con Ruby on Rails. Cuando se trata de migrar la base de datos, está todo claro: se crea una migración de esquema por cada tabla o modificación que queramos hacer, y cada una tiene su propio archivo. Según la documentación de RoR:
Las migraciones son una forma conveniente de modificar el esquema de tu base de datos a lo largo del tiempo de forma consistente. Utilizan un DSL de Ruby para que no tengas que escribir SQL a mano, permitiendo que tu esquema y los cambios sean independientes de la base de datos.
Pero… ¿qué pasa cuando queremos migrar datos? ¿Cuál es la mejor forma de hacerlo? Vamos a verlo 🙆♀️.
Lo que solíamos hacer
En el año 2020 entré a un proyecto chiquito, en el que, en teoría, sólo teníamos que hacer mantenimiento, así que todas las tareas que llegaban solían ser muy sistemáticas de resolver: creo esto, sumo esto otro, hago 2 o 3 cambios, testeo, fin.
Unos meses más tarde, empezamos a hacer cambios muy sustanciales en el core del proyecto sumando nuevos modelos que modificaban toda la estructura base de este. El problema principal era que ya teníamos mucha información de los últimos años en los que estuvo en curso el sistema (2 años para ser exacta), por lo tanto con la creación de estos nuevos modelos, teníamos que también migrar los datos.
Algunas de las ideas que se nos ocurrieron fueron:
Idea 1: Migrar datos por consola (#malaIdea 😵💫)
- No había forma simple de volver atrás (hacer rollback).
- No quedaba documentado el por qué, ni registro de haberlo hecho.
- No pasaba por revisión de código.
- Dependía de mí acordarme de ejecutar la consulta de forma manual al deployar los cambios.
Idea 2: Crear una tarea rake (no tan mala idea, pero no tan buena 👀)
- Quedaba documentada la consulta/actualización.
- Pasaba por revisión de código.
- Seguía dependiendo de mí acordarme de ejecutarla al deployar los cambios.
- No tenía sentido construir una tarea que sólo iba a ejecutar 1 vez en la vida del proyecto.
- No guarda relación con las migraciones de esquema: ¿Qué ejecuto primero?¿Qué pasa si necesito que la tarea rake se ejecute particularmente entre 2 migraciones de esquema?
- ¿Cómo controlo que nadie más corra la tarea nuevamente si ya fue ejecutada una vez? (recordemos que las migraciones de esquema cuentan con un estado “UP” que indica que ya fue ejecutada).
Idea 3: Incluir la consulta dentro de la migración de esquema
- Esto es algo que muchas veces hacemos cuando tenemos alguna dependencia para crear la migración, como en el caso que se quiera agregar una nueva columna con la condición de que no sea null, y existen registros que lógicamente aún no tienen la columna (y que por lo tanto no cumplen la condición). Por ejemplo:
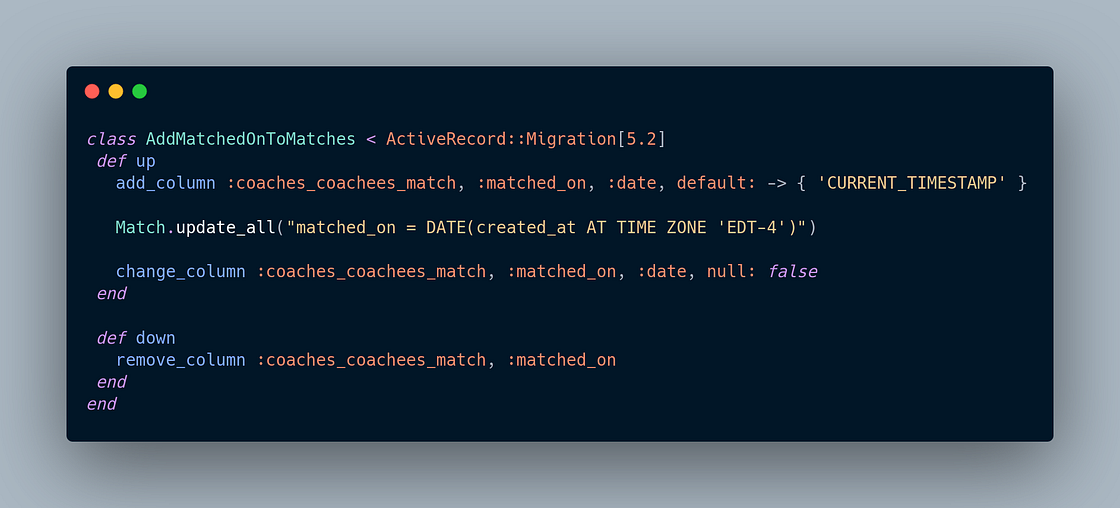
- Incluir la consulta acá parecía la opción más prometedora porque evitaba todas las contras de las ideas anteriores. Lo único que no nos terminaba de convencer era estar haciendo mucho más que una migración de esquema en un mismo archivo 🙄; era mucha responsabilidad para una misma cosa. Buscando alguna alternativa aún mejor, conocimos la gema data-migrate 🙌.
Lo que hacemos ahora
Como regla general, ya no hacemos migraciones de datos dentro de las de esquema, sino que ahora, gracias a la gema data-migrate, las migraciones de datos tienen su ubicación específica y separada del otro tipo de migraciones, en la carpeta db/data.
Para crearla por consola escribimos, por ejemplo:
rails g data_migration populate_discontinue_data_cohort_coachees
Lo que genera un archivo del estilo de las migraciones de esquema, con los métodos “up” y “down”, y que podemos completar con las consultas que sean necesarias. El siguiente ejemplo no tiene más de 3 líneas por método, pero otras veces hemos tenido migraciones que involucraron reunir datos de más de una tabla y quizás eran 100 líneas.

Por último, corremos la migración agregándole al comando tradicional “:with_data”
rails db:migrate:with_dataY listo! 🙌.
Ventajas de la gema data_migrate:
- Hace que nuestro código quede más limpio al tener todas las migraciones de datos ordenadas y agrupadas en una carpeta específica.
- Mantiene orden y coherencia con las migraciones de esquema (se corren en el orden que fueron creadas, intercalando ambos tipos de migración de ser necesario).
- Si tenemos un script que corre automáticamente las migraciones con cada deploy podemos simplemente agregarle el “:with_data” y despreocuparnos por correr una tarea extra.
- Tiene un sistema de rollback en caso de ser necesario (método down).
Contras de la usar la gema data_migrate:
- Añade una dependencia más al proyecto.
- No soporta múltiples DBs. En nuestro caso esto no es un problema, ya que tenemos sólo una, pero es algo a tener en cuenta.
En conclusión, las contras (si sólo manejás una base de datos) son prácticamente nulas comparadas a todas las grandes ventajas que presenta esta gema, así que la recomendamos 🏅.

